






名词解释#
endpoint:接入到网络中的设备称为 endpoint ❤️AS:网络自治系统,一个完全自治的网络,通过 BGP 协议与其它 AS 交换路由信息ibgp:AS 内部的 BGP Speaker,与同一个 AS 内部的 ibgp、ebgp 交换路由信息ebgp:AS 边界的 BGP Speaker,与同一个 AS 内部的 ibgp、其它 AS 的 ebgp 交换路由信息workloadEndpoint:Calico 网络中的分配虚拟机、容器使用的 endpointhostEndpoints:Calico 网络中的物理机(node)的地址
组网原理#
Calico 组网的核心原理就是IP路由,每个容器或者虚拟机会分配一个 workload-endpoint(wl)。
从 nodeA 上的容器 A 内访问 nodeB 上的容器 B 时:
+--------------------+ +--------------------+
| +------------+ | | +------------+ |
| | | | | | | |
| | ConA | | | | ConB | |
| | | | | | | |
| +-----+------+ | | +-----+------+ |
| | | | | |
| wl-A | | wl-B |
| | | | | |
+-------node-A-------+ +-------node-B-------+
| | | |
| | type1. in the same lan | |
| +-------------------------------+ |
| |
| type2. in different network |
| +-------------+ |
| | | |
+-------------+ Routers |-------------+
| |
+-------------+
从 ConA 中发送给 ConB 的报文被 nodeA 的 wl-A 接收,根据 nodeA 上的路由规则,经过各种 iptables 规则后,转发到 nodeB。
如果 nodeA 和 nodeB 在同一个二层网段,下一条地址直接就是 node-B,经过二层交换机即可到达。
如果 nodeA 和 nodeB 在不同的网段,报文被路由到下一跳,经过三层交换或路由器,一步步跳转到 node-B。
核心问题是,nodeA 怎样得知下一跳的地址?答案是 node 之间通过 BGP 协议交换路由信息。
每个 node 上运行一个软路由软件 bird,并且被设置成 BGP Speaker,与其它 node 通过 BGP 协议交换路由信息。
可以简单理解为,每一个 node 都会向其它 node 通知这样的信息:
我是X.X.X.X,某个IP或者网段在我这里,它们的下一跳地址是我。
通过这种方式每个 node 知晓了每个 workload-endpoint 的下一跳地址。
BGP 与 AS#
BGP 是路由器之间的通信协议,主要用于 AS(Autonomous System,自治系统)之间的互联。
AS,自治系统,是一个自治的网络,拥有独立的交换机、路由器等,可以独立运转。
每个 AS 拥有一个全球统一分配的 16 位的 ID 号,其中 64512 到 65535 共 1023 个 AS 号码被预留用于本地或者私用。
# calico默认使用的AS号是64512,可以修改:
# 查看
$ calicoctl config get asNumber
# 设置
$ calicoctl config set asNumber 64512
AS 内部有多个 BGP speaker,分为 ibgp、ebgp,ebgp 还与其它的 AS 中的 ebgp 建立 BGP 连接。
AS 内部的 BGP speaker 通过 BGP 协议交换路由信息,最终每一个 BGP speaker 拥有整个 AS 的路由信息。
BGP speaker 一般是网络中的物理路由器,calico 将 node 改造成了一个路由器(软件bird),node 上的虚拟机、容器等就是接入这个路由器的设备。
AS 内部的 BGP Speaker 之间有两种互联方式:
- 全互联模式模式
- Router reflection(RR) 模式
BGP Speaker全互联模式#
全互联模式,就是一个 BGP Speaker 需要与其它所有的 BGP Speaker 建立 bgp 连接(形成一个bgp mesh)。
网络中 bgp 总连接数是按照 O(n^2) 增长的,有太多的 BGP Speaker 时,会消耗大量的连接。
Calico 默认使用全互联的方式,扩展性比较差,只能支持小规模集群,可以打开/关闭全互联模式:
$ calicoctl config set nodeTonodeMesh off
$ calicoctl config set nodeTonodeMesh on
BGP Speaker RR 模式#
RR模式,就是在网络中指定一个或多个 BGP Speaker 作为 反射路由(Router Reflector),RR 与所有的 BGP Speaker 建立 bgp 连接。
每个 BGP Speaker 只需要与 RR 交换路由信息,就可以得到全网路由信息。
RR 必须与所有的 BGP Speaker 建立 BGP 连接,以保证能够得到全网路由信息。
在 Calico 中可以通过 Global Peer 实现 RR 模式。
Global Peer 是一个 BGP Speaker ,需要手动在 Calico 中创建,所有的 node 都会与 Global peer 建立 BGP 连接。
关闭了全互联模式后,再将 RR 作为 Global Peers 添加到 Calico 中,Calico 网络就切换到了 RR 模式,可以支撑容纳更多的 node。
RR 模式部署#
集群环境:
| IP | 主机名 |
|---|---|
| 10.10.31.190 | kube-master |
| 10.10.31.193 | kube-node1 |
| 10.10.31.194 | kube-node2 |
| 10.10.31.168 | node1 |
在 node1 节点上启动反射路由实例#
$ docker run --privileged --net=host -d \
-e IP=<IPv4_RR> \
[-e IP6=<IPv6_RR>] \
-e ETCD_ENDPOINTS=<https://ETCD_IP:PORT> \
-v <FULL_PATH_TO_CERT_DIR>:<MOUNT_DIR> \
-e ETCD_CA_CERT_FILE=<MOUNT_DIR>/<CA_FILE> \
-e ETCD_CERT_FILE=<MOUNT_DIR>/<CERT_FILE> \
-e ETCD_KEY_FILE=<MOUNT_DIR>/<KEY_FILE> \
calico/routereflector:v0.4.0
# <FULL_PATH_TO_CERT_DIR> 是你的宿主机的 etcd 证书和秘钥的存放目录
配置反射路由的集群#
反射路由关于 ipv4 的配置在 etcd 中的存储路径为:
/calico/bgp/v1/rr_v4/<RR IPv4 address>
ipv6 的配置在 etcd 中的存储路径为:
/calico/bgp/v1/rr_v6/<RR IPv6 address>
数据格式为 json:
{
"ip": "<IP address of Route Reflector>",
"cluster_id": "<Cluster ID for this RR (see notes)>"
}
通过 curl 将该条目添加到 etcd 中
# IPv4 entries
$ curl --cacert <path_to_ca_cert> --cert <path_to_cert> --key <path_to_key> -L https://<ETCD_IP:PORT>:2379/v2/keys/calico/bgp/v1/rr_v4/<IPv4_RR> -XPUT -d value="{\"ip\":\"<IPv4_RR>\",\"cluster_id\":\"<CLUSTER_ID>\"}"
# IPv6 entries
$ curl --cacert <path_to_ca_cert> --cert <path_to_cert> --key <path_to_key> -L https://<ETCD_IP:PORT>:2379/v2/keys/calico/bgp/v1/rr_v6/<IPv6_RR> -XPUT -d value="{\"ip\":\"<IPv6_RR>\",\"cluster_id\":\"<CLUSTER_ID>\"}"
例如:
$ curl --cacert <path_to_ca_cert> --cert <path_to_cert> --key <path_to_key> -L https://10.10.31.190:2379/v2/keys/calico/bgp/v1/rr_v4/10.10.31.168 -XPUT -d value="{\"ip\":\"10.10.31.168\",\"cluster_id\":\"1.0.0.1\"}"
配置 calico 使用反射路由#
关闭全互联模式
$ calicoctl config set nodeToNodeMesh off
确定你的网络的 AS 号码
$ calicoctl get nodes --output=wide
# 或者使用以下命令
$ calicoctl config get asNumber
将 RR 作为 Global Peers 添加到 Calico 中
$ calicoctl create -f - << EOF
apiVersion: v1
kind: bgpPeer
metadata:
peerIP: <IP_RR>
scope: global
spec:
asNumber: <AS_NUM>
EOF
# <IP_RR>:反射路由的 ipv4 或 ipv6 地址
# <AS_NUM>:网络的 AS 号码
由于 BGP 协议使用 TCP 179 端口进行通信,可以在 node1 上查看一下
$ ss -tnp|grep 179
ESTAB 0 0 10.10.31.168:179 10.10.31.196:55967 users:(("bird",pid=10601,fd=8))
ESTAB 0 0 10.10.31.168:56393 10.10.31.193:179 users:(("bird",pid=10601,fd=9))
ESTAB 0 0 10.10.31.168:41164 10.10.31.194:179 users:(("bird",pid=10601,fd=10))
在 node1 上查看反射路由配置
$ docker exec 52e584f5bcf3 cat /config/bird.cfg
# Generated by confd
router id 10.10.31.168;
# Watch interface up/down events.
protocol device {
scan time 2; # Scan interfaces every 2 seconds
}
# Template for all BGP clients
template bgp bgp_template {
debug off;
description "Connection to BGP peer";
multihop;
import all; # Import all routes, since we don't know what the upstream
# topology is and therefore have to trust the ToR/RR.
export all; # Export all.
source address 10.10.31.168; # The local address we use for the TCP connection
graceful restart; # See comment in kernel section about graceful restart.
}
# ------------- RR-to-RR full mesh -------------
# For RR 10.10.31.168
# Skipping ourselves
# ------------- RR as a global peer -------------
# This RR is a global peer with *all* calico nodes.
# Peering with Calico node node1
protocol bgp Global_10_10_31_193 from bgp_template {
local as 64512;
neighbor 10.10.31.193 as 64512;
rr client;
rr cluster id 1.0.0.1;
}
# Peering with Calico node node2
protocol bgp Global_10_10_31_194 from bgp_template {
local as 64512;
neighbor 10.10.31.194 as 64512;
rr client;
rr cluster id 1.0.0.1;
}
# Peering with Calico node node3
protocol bgp Global_10_10_31_196 from bgp_template {
local as 64512;
neighbor 10.10.31.196 as 64512;
rr client;
rr cluster id 1.0.0.1;
}
# ------------- RR as a node-specific peer -------------
在 kube-node1 上查看 calico 的配置
$ docker exec 7fcb072515d6 cat /etc/calico/confd/config/bird.cfg
# Generated by confd
include "bird_aggr.cfg";
include "custom_filters.cfg";
include "bird_ipam.cfg";
router id 10.10.31.193;
# Configure synchronization between routing tables and kernel.
protocol kernel {
learn; # Learn all alien routes from the kernel
persist; # Don't remove routes on bird shutdown
scan time 2; # Scan kernel routing table every 2 seconds
import all;
export filter calico_ipip; # Default is export none
graceful restart; # Turn on graceful restart to reduce potential flaps in
# routes when reloading BIRD configuration. With a full
# automatic mesh, there is no way to prevent BGP from
# flapping since multiple nodes update their BGP
# configuration at the same time, GR is not guaranteed to
# Watch interface up/down events.
protocol device {
debug { states };
scan time 2; # Scan interfaces every 2 seconds
}
protocol direct {
debug { states };
interface -"cali*", "*"; # Exclude cali* but include everything else.
}
# Template for all BGP clients
template bgp bgp_template {
debug { states };
description "Connection to BGP peer";
local as 64512;
multihop;
gateway recursive; # This should be the default, but just in case.
import all; # Import all routes, since we don't know what the upstream
# topology is and therefore have to trust the ToR/RR.
export filter calico_pools; # Only want to export routes for workloads.
next hop self; # Disable next hop processing and always advertise our
# local address as nexthop
source address 10.10.31.193; # The local address we use for the TCP connection
add paths on;
graceful restart; # See comment in kernel section about graceful restart.
}
# ------------- Global peers -------------
# For peer /global/peer_v4/10.10.31.168
protocol bgp Global_10_10_31_168 from bgp_template {
neighbor 10.10.31.168 as 64512;
}
# ------------- Node-specific peers -------------
多 cluster ID 实例拓扑#
当拓扑包含了多个反射路由时,BGP 利用集群 id 来保证分配路由时不陷入循环路由。
反射路由镜像帮助每个反射路由提供固定的集群 id 而不是依赖单一平行原则进行配置,这简化了整个网络的配置,但也给拓扑带来了一些限制:
The Route Reflector image provided assumes that it has a fixed cluster ID for each Route Reflector rather than being configurable on a per peer basis.
For example, the topology outlined in the diagram below is based on the Top of Rack model:
- Each rack is assigned its own cluster ID (a unique number in IPv4 address format).
- Each node (server in the rack) peers with a redundant set of route reflectors specific to that rack.
- All of the ToR route reflectors form a full mesh with each other.
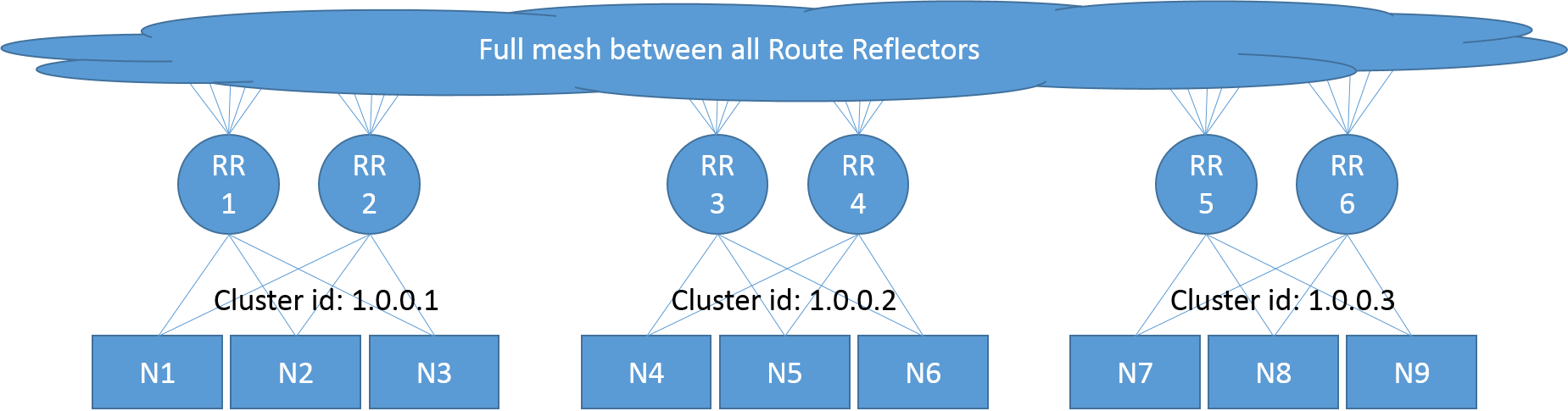
For example, to set up the topology described above, you would:
- Spin up nodes N1 - N9
- Spin up Route Reflectors RR1 - RR6
- Add node specific peers, peering:
N1, N2 and N3 with RR1 and RR2
N4, N5 and N6 with RR3 and RR4
N7, N8 and N9 with RR5 and RR6 - Add etcd config for the Route Reflectors:
RR1 and RR2 both using the cluster ID 1.0.0.1
RR2 and RR3 both using the cluster ID 1.0.0.2
RR4 and RR5 both using the cluster ID 1.0.0.3